Синхронизация данных
В разных проектах часто возникает задача синхронизации данных между устройствами. Если синхронизация целиком всей БД одним файлом не подходит[^1], то нужно реализовать более гибкое решение.
Для решения проблемы синхронизации отдельных записей из локальной БД и был разработан описанный в этом документе протокол синхронизации. Реализация протокола должна быть легко переносимой, чтобы можно было использовать её в разных проектах с минимальными изменениями.
[^1]: Такой вариант может подойти например для сейва игры, но не для условных Записок.
Содержание
- Введение
- Постановка задачи
- Базовая концепция
- Процесс синхронизации
- Алгоритм синхронизации
- Запрос и валидация даты
- Выгрузка изменений с клиента
- Загрузка обновленных сущностей с сервера
- Синхронизация файлов
- Реализация
- Объекты
- Файлы
- Отладка
- Проблемы при синхронизации
- Проблема идентификаторов
- Проблема большого объема данных
- Проблема разрыва соединения
- Связи сущностей
- Определение времени модификации
- Получение данных с сервера
- Развитие
- Материалы
Введение
Будем исходить из того, что клиент имеет локальную БД (обычно SQLite, но это не принципиально) с записями, которые (или, чаще всего, часть из которых) нужно синхронизировать.
Постановка задачи
Нужно синхронизировать записи для одного пользователя между его устройствами.
Требования/ограничения:
- Синхронизация через наш сервер.
- Приложение должно работать офлайн.
- Устойчивость к прерыванию соединения во время синхронизации.
- Эффективность по скорости и объему пересылаемых данных.
- Синхронизация должна продолжать работать после любых ошибок (не ломаться).
- Пользователь не должен решать конфликты вручную.
- Результат слития должен соответствовать ожиданиям пользователя.
- История изменений не важна.
Базовая концепция
- Каждое устройство хранит свою локальную копию.
- Сервер хранит основную копию.
- Сервер решает конфликты.
- Клиент записывает факты изменения сущности, но хранит только текущий вариант.
- Сервер хранит данные о последнем изменении каждого поля каждой сущности (метаданные).
Процесс синхронизации
- Клиент выгружает лог изменений и текущее состояние сущности на сервер.
- Сервер обрабатывает изменения, решает конфликты и обновляет текущее состояние сущностей.
- Сервер присылает на клиент все измененные со времени последней синхронизации сущности.
- Клиент обновляет у себя изменившиеся сущности.
Алгоритм синхронизации
Алгоритм синхронизации включает 3 основных этапа.

Запрос и валидация даты
Клиент запрашивает с сервера текущую дату, для проверки и приведения в порядок дат модификации. См. Определение времени модификации.
- Запрос на получение даты.
- Если полученная дата отличается[^2] от текущей рассчитываемой, то:
- обновляем значение даты в записях для синхронизации;
- записываем новое значение сдвига и текущую дату (как дату последнего получения времени).
[^2]: С учетом погрешности.
Далее в качестве даты модификации везде фигурирует текущая рассчитываемая дата. Такая дата рассчитывается как текущая клиентская + сдвиг, что должно соответствовать серверной дате.
Выгрузка изменений с клиента
Выгрузка изменений с клиента происходит частями (см. Проблему большого объема данных).
Чтобы выделить часть изменений, которые требуется синхронизировать, будем использовать Update Sequence Number.
Update Sequence Number (USN) — для каждой записи действия отмечается номер изменения, он также влияет на порядок применения. Максимальный номер равен полному числу изменений. Хранится только на клиенте, на сервере не записывается (т.к. у разных клиентов будет разный USN).
Как происходит процесс выгрузки:
- Выбирается N событий для синхронизации, с USN больше последнего отправленного.
- Если событий нет — то процесс завершается, если есть, то продолжаем.
- Выбранные события отправляются на сервер.
- Сервер обрабатывает их и возвращает последний обработанный USN.
- Клиент записывает полученный USN как последний отправленный.
- Переходим к шагу 1.
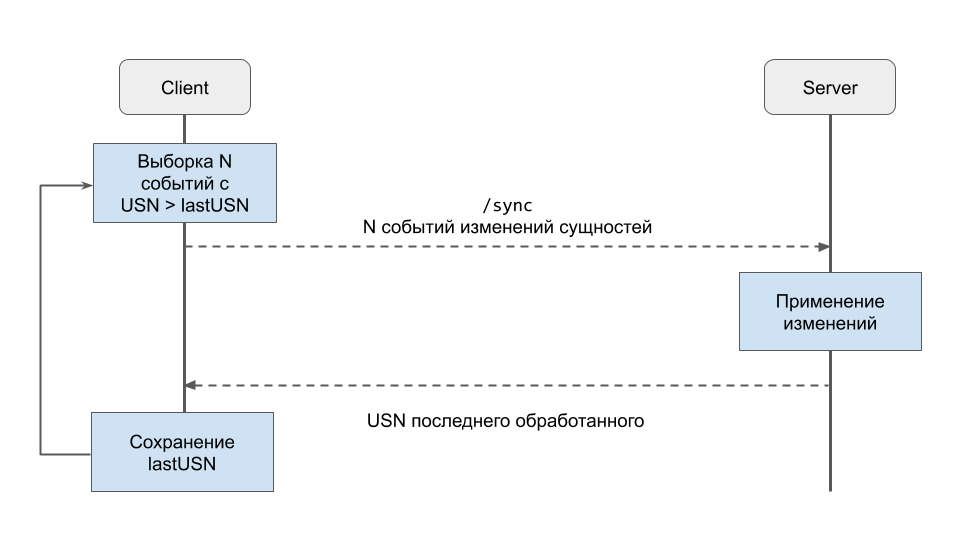
Применение изменений на сервере
Если изменения с разных клиентов применяются к разным сущностям (или изменения есть только с одного клиента), то изменения применяются к сущности без дополнительной обработки. Сложности возникают когда мы имеем изменения у одной и той же сущности, сделанные с разных клиентов (речь идет, конечно, о конкурентных изменениях, т.е. когда клиент A не успел синхронизировать изменения, которые были сделаны на клиенте B).
Слитие сущностей
Если в сущности меняются разные поля, то они просто сливаются, без конфликта.
Пример: в заметке на устройстве A изменили текст, а на устройстве B — добавили тему. В итоге я ожидаю заметку, у которой будет текст с A устройства, а тема — с B устройства.
Конфликт возникает, если меняется одно и то же поле.
Решение конфликтов
- Для каждого свойства заводим дату изменения.
- Побеждает то изменение, дата которого позже.
Пример: если я днём изменил дату напоминания на устройстве A, а вечером пришел домой и поменял дату напоминания на устройстве B, то ожидаемое поведение после синхронизации — получить дату напоминания, которую я задал последней (т.е. с устройства B).
⚠️ Важно! Нужно учитывать именно время модификации, а не синхронизации. В примере выше устройство A у меня может быть без подключения к сети, и синхронизация пройдет позже, чем для устройства B. Но при этом дата напоминания не должна быть переписана.
Disclaimer
Принцип "just works" имеет свою цену: он предоставляет супер удобный и простой способ синхронизации в обычном случае, но может доставлять много проблем в каких-то крайних случаях. Мы это понимаем и идем на это осознанно.
Блокировка
Важно учесть, что пока выполняется синхронизация (применение изменений) с одного клиента, то запросы на синхронизацию от всех прочих клиентов должны блокироваться, иначе это может привести к непредсказуемым последствиям.
Предпочтительный метод: - ставим запросы клиентов в очередь, чтобы одновременно выполнялся только один; - если запрос долго находится в очереди (например больше 5 секунд), то возвращаем на клиент ошибку, которая явно говорит клиенту о том, что сейчас синхронизация заблокирована и надо повторить попытку позднее.
⚠️ Важно! Очередь надо делать только по конкретному пользователю. Нельзя блокировать запросы на синхронизацию от других пользователей.
Загрузка обновленных сущностей с сервера
После того, как с клиента были выгружены все изменения, отправляется запрос на получение сущностей, которые изменились на сервере с момента последней синхронизации. В качестве параметра передается токен синхронизации (см. Получение данных с сервера) или null, если нет сохраненного токена.
Сервер выбирает M сущностей (см. Проблему большого объема данных), которые были обновлены с момента последней синхронизации клиента (включая те, что изменил сам клиент) и отправляет их, а также новый токен синхронизации и флаг, отмечающий есть ли еще обновления, в ответ клиенту.
Флаг нужен для того, чтобы клиент понимал, нужно ли сразу делать следующий запрос, чтобы догрузить оставшиеся изменения, или все изменения уже присланы.
Следует обратить внимание, что сервер, в отличие от клиента, присылает не действия изменения по полям, а уже готовые объекты сущностей, который должны быть просто заменены, а весь лог изменений для них — очищен (или обновлен так, чтобы при следующей выгрузке он не был выбран для отправки). Т.к. слитие и решение конфликтов выполняет именно сервер — только он знает реальное состояние объектов и надежнее будет обновлять их целиком.
⚠️ Важно! Учитывая, что сервер присылает не все сущности сразу, а частями, для него актуальна проблема разрыва соединения, которая может привести к тому, что не все объекты будут выгружены. А это означает, что часть объектов на клиенте может ссылаться на еще несозданные объекты (см. Проблему связи сущностей). Поэтому клиент должен уметь обрабатывать корректно такие сущности.
Эта проблема частично решена введением сущности связи, которая позволяет синхронизировать связи между сущностями отдельно от полей сущностей, что позволяет избежать ситуации когда в поле есть ссылка на несуществующую запись. Но даже при этом нужно учитывать, что могут быть связи, которые ссылаются на несуществующие записи, и обрабатывать их корректно.
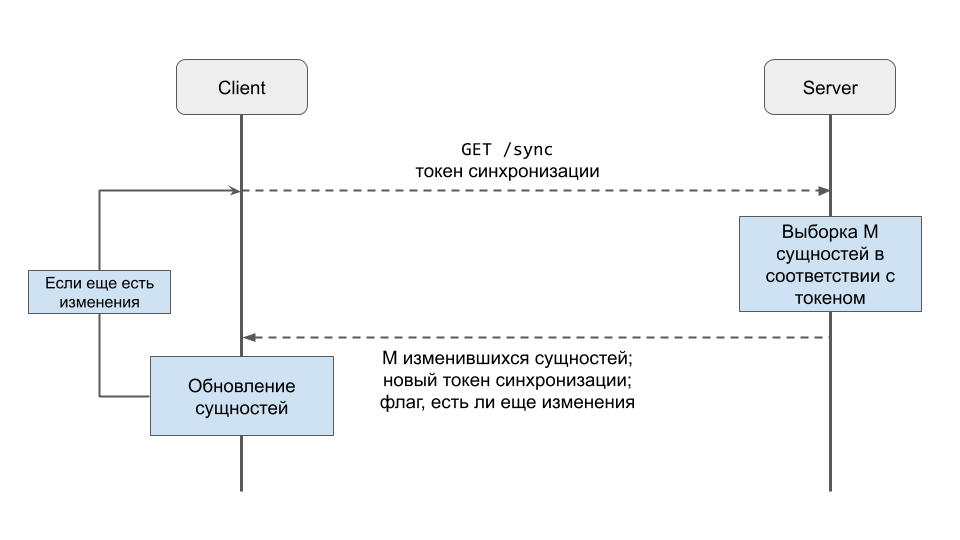
Если во время загрузки данных на клиенте произошли изменения, клиент должен проигнорировать (отменить) этот запрос данных и начать выгружать свои изменения. И только после выгрузки всех своих изменений, снова перезапросить данные.
⚠️ На клиенте нужно учитывать, что новые данные могут прийти, например, во время редактирования сущности. Нужно либо реализовать функционал так, чтобы этого не происходило (не загружать данные пока идет редактирование), либо обработать такой момент.
Синхронизация файлов
Синхронизация файлов происходит параллельно: по алгоритму мы синхронизируем только сущности для файлов, а дальше сами файлы выгружаются параллельно всему процессу в общей очереди.
Реализация
Объекты
Клиент
Действие изменения
SyncAction
{
long usn // Update Sequence Number
String entityUid // Идентификатор сущности
String entityType // Тип сущности
DateTime date // Дата действия (пересылается на сервер с точностью до мс)
String type = 'add|update|link|unlink' // Тип действия: добавление или обновление сущности, или установка/удаления связи
String fieldName // Название поля (не пересылается для типа 'add'), для действия со связью хранит тип связанной сущности
String fieldValue // Значение поля (не пересылается для типа 'add'), для действия со связью хранит uid связанной сущности
}
При создании сущности отправляется одно событие с типом add и по событию update для каждого поля (значения по умолчанию желательно не пересылать).
⚠️ Если было несколько изменений конкретного поля, то хранится и отправляется на сервер только одно, последнее.
В качестве даты действия здесь используется нормализованная дата, с учетом сдвига (см. Определение времени модификации). При записи обязательно надо проверить, чтобы дата была больше либо равна последней дате модификации.
Удаление сущности делается флагом, поэтому отдельный тип для удаления пока не вводится.
Данные для синхронизации
SyncData
{
long usn // Текущее значение USN
long lastSyncedUsn // Последний обработанный сервером USN
String syncToken // Токен синхронизации с сервера
DateTime syncDate // Дата последней синхронизации (получения syncToken)
DateTime lastModifiedDate // Последняя дата модификации
long serverDateOffset // Сдвиг между серверным и клиентским временем
DateTime lastServerDate // Дата последний раз полученная от сервера (когда был рассчитан сдвиг)
}
lastModifiedDate представляет собой нормализованную по сдвигу дату и используется для проверки при записи даты модификации для сущности. Следует учитывать, что при обновлении времени с сервера, если калибруются даты модификации сущностей, то и эта дата должна быть откалибрована.
Здесь указаны только ключевые поля, требуемые для синхронизации, в реальной реализации может быть больше полей.
Сервер
ℹ️ Все действия на сервере рассматриваются в контексте конкретного аккаунта. Т.е. имеется ввиду, что сущности принадлежат конкретному пользователю, данные хранилища соответствуют конкретному пользователю и так далее.
Метаданные сущности
На сервере для каждой синхронизируемой сущности хранится объект метаданных для синхронизации, который включает информацию о дате модификации для всех изменяемых полей.
Например, для сущности Entity с полями:
Entity
{
String uid // Идентификатор сущности
// Поля сущности
String title
int color
bool removed
}
Должен быть объект метаданных:
EntitySyncMeta
{
String uid // Идентификатор сущности
Date created // Дата создания сущности
Date modified // Дата последней модификации сущности
long revision // Глобальная ревизия хранилища (аналог USN на клиенте)
// Даты изменения по отдельным полям
DateTime titleModified
DateTime colorModified
DateTime removedModified
}
Данные хранилища
StorageData
{
long revision // Текущая ревизия хранилища
}
Файлы
Здесь приведён вариант реализации синхронизации файлов, который реализован у нас в проекте.
Общее описание
- Для каждого файла (вне зависимости, включена синхронизация или нет) создается сущность
SyncFile. Сущность описывает сам файл, синхронизируется как любая другая сущность. - После того как запись выгружена на сервер, клиент будет пытаться закачать файл на сервер (это может быть не сразу, как будет возможность), с указанием
uidэтой сущности. - Для сущностей файлов, полученных с сервера, клиент попытается выполнить загрузку — скачать файл (тоже не известно в какой момент).
Сущность файла
SyncFile
{
String uid // Идентификатор сущности
Date created // Дата создания сущности
Date modified // Дата последней модификации сущности
bool removed // Отмечена ли сущность как удаленная
String fileType // Тип файла, по которому будет определяться директория для размещения
String localPath // Расположение файла на устройстве относительно базового пути
String remotePath // Путь на сервере (не присылается с клиента, заполняется сервером)
}
Выгрузка файла на сервер
Отправляется запрос /sync/upload: файл отправляется как часть multipart/form-data, кроме файла также передается DTO данных:
{
"uid": "..."
}
В ответ приходит:
{
"uid": "...",
"remotePath": "..."
}
После того как файл был загружен на сервер — сервер обновляет у сущности значение remotePath и возвращает эту сущность как обновленную при запросе обновленных сущностей клиентом. Дополнительно в объекте данных сущностей файла пересылается базовый URL, к которому надо добавить remotePath, для того, чтобы получить URL файла.
Особенности хранения файлов на сервере
Имя для хранения на сервере определяет сам сервер. В качестве имени может выступать рандомная строка или uid — localPath лучше не использовать (единственное, возможно стоит сохранять расширение).
Путь хранения файлов будет по сути публичный, поэтому нельзя допустить чтобы можно было "угадать" путь до файлов другого пользователя, или с какой-то значимой вероятностью увидеть файлы случайного пользователя. Т.е. нужна максимальная рандомность. При этом файлы имеет смысл объединять по пользователю (лучше использовать не числовой id, а какой-нибудь хэш например).
При повторной загрузке файла с клиента — текущий файл перезаписывается.
Скачивание файла с сервера
Если на клиент приходит сущность файла, для которой заполнен remotePath и при этом файл локально не существует — этот файл будет скачан при возможности.
Скачивание происходит по URL, который состоит из базового URL файлов с добавлением remotePath сущности. По этому URL на сервере должен быть доступен нужный файл.
Привязка файла к сущности
Обычно файл должен относиться к какой-то другой сущности, например к сущности аудио вложения в заметку относится сам аудио файл. В таком случае основная сущность связывается с сущностью файла как любые другие 2 сущности (в зависимости от выбранного механизма, либо с помощью поля fileUid, либо с помощью отдельной сущности связи).
Отладка
Для отладки механизма синхронизации нужно писать логи и ошибки. Давайте рассмотрим основные ситуации, которые надо отлаживать.
Синхронизация
Больше всего проблем, особенно на первом этапе, может возникнуть с синхронизацией, слиянием сущностей и разрешением конфликтов. Для того, чтобы иметь возможность отладки, сервер должен записывать следующие данные: - Все действия, которые присылаются с клиента.
Сбой времени
В случае сбоя времени на сервере весь процесс синхронизации может сломаться, поэтому очень важно отслеживать такие ситуации.
Нужно: - валидировать время на сервере, чтобы отловить сбой; - записывать лог такой ситуации; - оповещать о том, что ситуация произошла, чтобы можно было быстро отреагировать на нее.
Проблемы при синхронизации
Описанный выше алгоритм в реализации решает или учитывает ряд проблем, возникающих при синхронизации данных. В этом разделе подробно описаны такие проблемы, с пояснениями и примерами.
Проблема идентификаторов
Так как записи создаются локально, возникает проблема идентификаторов: мы не можем использовать автоинкремент, т.к. никто не гарантирует нам, что на другом устройстве не будет (или не была) создана запись с таким идентификатором.
⚠️ Важно! Следует учитывать то, что пользователь может выйти из аккаунта и создать новый, синхронизировав заметки теперь с ним, или вернуться в старый и продолжить синхронизацию после перерыва.
Один из вариантов решения проблемы: строковые идентификаторы (возможно стоит рассмотреть числовые), сгенерированные случайным образом. Вероятность что такие идентификаторы повторятся чрезвычайно мала и это простой способ.
⚠️ Важно! На сервере в качестве уникального ключа надо рассматривать не сам ID, а сочетание идентификатора сущности с идентификатором пользователя, это исключит вероятность конфликтов между данными разных пользователей на большой базе, при намеренной отправке каких-то идентификаторов от "плохого" клиента или при перелогине пользователя под другим аккаунтом с теми же данными.
Второй способ чуть сложнее, но полностью исключает возможность конфликта и гораздо эффективнее по размеру хранимых данных (можно хранить число, а не строку в качестве идентификатора). Каждая синхронизируемая запись должна иметь локальный идентификатор (генерирует тот, кто создает) и глобальный идентификатор (uid на сервере), который будет получен с сервера при синхронизации. Это предпочитаемый способ[^3], хотя он и может несколько усложнить синхронизацию связанных сущностей.
[^3]: Для будущей реализации протокола, в первой версии используются генерируемые строковые идентификаторы, по историческим причинам.
Проблема большого объема данных
При синхронизации нужно выгружать с клиента и загружать на клиент некоторый объем данных. Учитывая что объем данных может быть достаточно большой, то если выгружать сразу все данные — это может привести к большим проблемам при слабом интернет-соединении.
Давайте рассмотрим пример. Пусть пользователь долго использовал приложение и накопил большой объём данных (до 100 МБ например), а затем решил создать аккаунт. В этот момент ему потребуется разово выгрузить все данные, что при слабом интернет соединении (мобильном интернете например) и ограниченном времени (в том числе времени использования приложения) может быть просто невозможно. А так как данные грузятся только целиком, то попытка будет повторяться многократно, пока все 100 МБ не выгрузятся за раз.
Справедливо и обратное — если у пользователя уже есть большой объем данных на сервере, то при входе в аккаунт с нового устройства ему придется за один запрос скачать 100 МБ, что также может быть весьма затруднительно.
Таким образом и выгрузку и загрузку данных при синхронизации надо делать по частям.
Проблема разрыва соединения
При выгрузке (загрузке) данных по частям остро встает вопрос разрыва соединения (или закрытия приложения, в данном контексте — одно и то же). Если пользователь загрузил часть данных, а потом произошел разрыв, то он недополучит все данные. При этом приложение должно:
- Продолжать корректно работать в офлайн режиме.
- После восстановления соединения продолжить синхронизацию.
Также из-за разрыва может возникнуть ситуация когда клиент загрузил не все данные с сервера, но у него уже произошли новые изменения. В таком случае он отправит новые изменения до того, как догрузить оставшиеся данные.
Связи сущностей
При синхронизации нужно учитывать что сущности могут быть связаны друг с другом. Например, сущность заметки имеет ссылку на сущность темы. При этом связь сущностей друг с другом может быть закольцована: Obj1 ссылается на Obj2, Obj2 на Obj3, а Obj3 на Obj1.
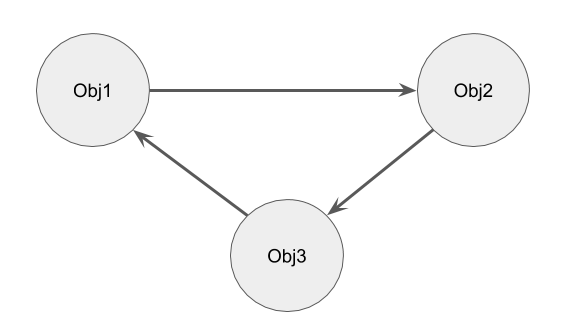
Почему это важно? Такие ситуации нужно иметь ввиду при синхронизации, т.к. если мы синхронизируем значения полей в произвольном порядке, то, при прерывании синхронизации, может получиться ситуация когда в поле есть ссылка на несуществующую запись.
Определение времени модификации
С определением времени модификации есть одна очень важная проблема: часам на устройстве пользователя нельзя доверять. Они могут идти неточно или быть переведены намеренно, что сломает механизм синхронизации.
Для решения существует несколько подходов. Первый: получать и проверять время с помощью сервера времени. Но такой способ сильно завязан на интернет соединение. Поэтому мы выберем второй: получать время с сервера при синхронизации, сравнивать с текущим клиентским и получать сдвиг, который затем используется при расчете реального времени модификации.
У такого способа тоже есть проблемы. - Сдвиг может меняться между сеансами синхронизации. - Сдвиг должен учитывать время на запрос.
Вторая проблема решается достаточно просто. При расчете мы можем считать что дата, которую присылает сервер соответствует текущей дате минус половина продолжительности запроса. Это должно обеспечить достаточную точность в подавляющем большинстве случаев.
Первая проблема сложнее. Её мы попробуем решить (точнее уменьшить) постоянной калибровкой значения сдвига и проверками. - Перед запросом синхронизации клиент получает от сервера дату и рассчитывает сдвиг. - Если на клиенте есть записи с датой больше текущей — то выставляем им всем текущую дату. - Сервер должен проверять время модификации для синхронизируемых записей. - Если находятся записи, с датой изменения старше текущей, нужно вернуть ошибку. Клиент должен обработать эту ошибку и пересчитать время. - После синхронизации клиент еще раз запрашивает дату с сервера (также дату можно получать в ответ). Это должно гарантировать что при следующей синхронизации на сервер не будут посланы записи с датой модификации, которая раньше, чем у уже синхронизированных.
⚠️ Важно! Дата на сервере должна быть правильной и не должна меняться.
При расчете даты модификации сущности мы используем полученный сдвиг. Но следует учитывать что часы можно сдвинуть и после последнего расчета сдвига, поэтому нужно проверять, не пытаемся ли мы записать дату модификации, которая меньше, чем уже записанная. Дата модификации сущности всегда должна быть больше, либо равна максимальной из уже записанных дат модификации.
Получение данных с сервера
Клиент должен получить с сервера не все сущности, а только измененные со времени последней синхронизации. Это можно реализовать через прямую передачу времени, старше которой надо получить изменения, или с помощью токена синхронизации. Второй способ выглядит более универсальным и легче расширяется, так что остановимся на нём.
- При ответе с сервера вместе с данными присылается токен синхронизации.
- Токен синхронизации запоминается на клиенте.
- При следующем запросе данных клиент отправляет сохраненный токен синхронизации.
Что представляет собой токен синхронизации?
Это строка, в которой закодирована необходимая информация. Клиент не декодирует эту строку, а просто хранит и пересылает её. Сервер же напротив, не сохраняет токен, а декодирует полученный и на основании полученной информации делает выборку.
Токен представляет собой закодированную в base64 строку формата: {version}:{unixtime_ms}:{revision}, где {version} — версия формата токена, {unixtime_ms} — unixtime в миллисекундах, а {revision} — номер ревизии хранилища. Например: 1:1578910108134:12345.
Развитие
Это базовая версия протокола, она предполагает дальнейшее развитие. Вот в каких направлениях можно работать:
- Использовать не HTTP+JSON, а что-то более оптимизированное, чтобы уменьшить объем пересылаемых данных.
- Отдельный, более продвинутый, алгоритм решения конфликтов для некоторых полей, например, текста заметки.
- Использование отдельной сущности связи, вместо связи сущностей полями (это решит проблему частичной синхронизации с сервера на клиент) — сделано ✅ (TODO: описать в документации подробнее)
- Полное удаление сущности (отдельный тип действия).
- Для экономии данных возможно стоит объединить идущие подряд
SyncActionпо сущности. - Следует обработать момент, что при первой синхронизации нам важнее более новые элементы (которые менялись недавно) и их нужно загружать в первую очередь.
Материалы
При разработке использовались следующие материалы:
- Vesper Sync Diary #5 - Sync Tokens and Efficiency
- Vesper Sync Diary #6 - Merging Notes
- Vesper Sync Diary #8 - The Problem of Unique IDs
- Evernote full sync specification
- Clear in the iCloud
- A Sync Case Study
- Синхронизация данных на мобильных платформах
- OMA DS Concepts and Definitions
- OMA A Primer to SyncML/OMA DS
Дополнительные материалы
Дополнительные материалы, которые также можно использовать для погружения в тему синхронизации: